Stop Wasting Working Software
Josh Burgess •
#domain-driven-design#microservices#docker#api#cloud-computing

Architecting Distributed Systems
Creating a Software Ecosystem with API Gateways, Service Meshes, and Message Queues Utilizing a Strangler Fig Pattern
The field of software engineering is dynamic and constantly evolving. As we progress, the way we design and develop new systems also changes rapidly. Cloud Native systems are appealing to companies because of the pay-per-use pricing model, the agility it gives to release features fast, ease of scalability, and evolvability. This choice to lift and shift workloads to the cloud can also involve moving Legacy (applications or services that still need to be updated to fit the current engineering architecture of choice) systems to the cloud, which can hold great importance to the business. If we need to improve this system, it can be frustrating and challenging for engineers to revisit legacy code that might be inflexible due to its initial design. This can lead to headaches and delays in improving the services. The initial thought is — rebuild it and wait for the new one to be done. What if this does not have to be the case? This article is going to cover the Strangler Fig Pattern, Domain-Driven-Design to plan out application teams and services, and how choice of technology can help decoupling a large-scale system. I will be building out a sample project to help follow along with some of these concepts, and by the end of this article, you will have these tools running locally in a simple sample project.
Prerequisites
If you would like to follow along with the tutorial:
- Docker and optionally Docker Desktop
- Git
- Clone my repo https://github.com/joshbrgs/medium-tutorials/tree/stop-wasting-software
- Optionally Postman
Why do I want a Software Ecosystem?
A software ecosystem is a pattern to reuse backend systems and services to help bootstrap the development of newer applications and features. If your company has a production-vetted service to process payments, why would you create a whole new one just yet?
…every piece of knowledge must have a single, unambiguous, authoritative representation within a system. ~ The Pragmatic Programmer
As an engineer, you want to be a good steward of technology and not let broken windows (out of date code or functionality that does not need to exist) into your code base; so, you will want to re-engineer older services and phase them out in favor of your more optimized solution. An advantage of a well-architected ecosystem of services, you can A/B test the service to gradually introduce it. Let’s also be true to ourselves, it is often fast and easier to just start from scratch than it is to surgically remove important pieces of legacy code.
The Strangler Fig Pattern
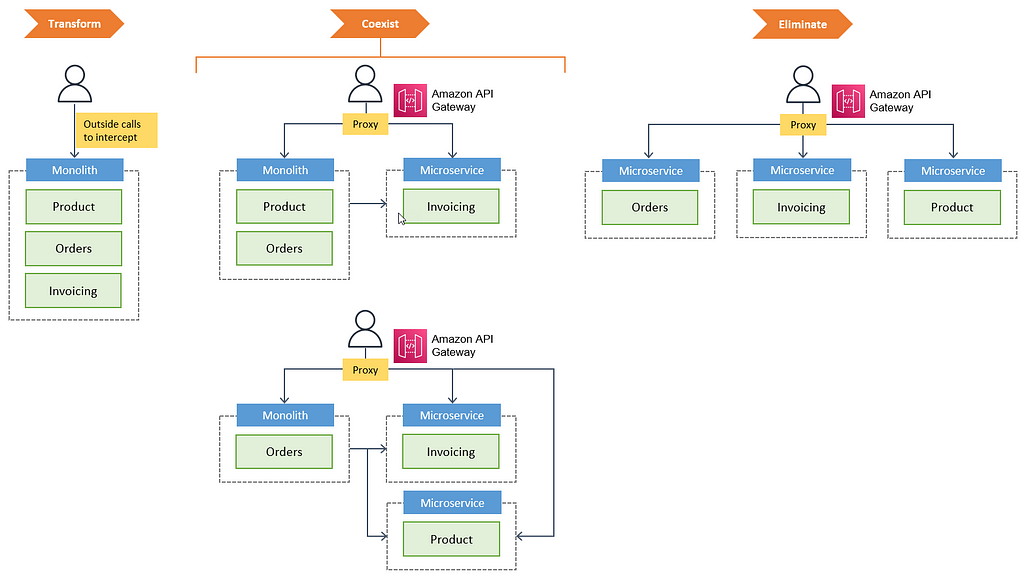
As business grows and your market’s interest change, you may want to release a new and improved application, which gives you a couple of common choices — cut-over rewrite or the strangler fig pattern. As engineers, we love rewriting legacy software to utilize new technologies (fka brownfield projects).
The most important reason to consider a strangler fig application over a cut-over rewrite is reduced risk. A strangler fig can give value steadily and the frequent releases allow you to monitor its progress more carefully. ~ Strangler Fig Application — Martin Fowler, 29 June 2004
As the above illustration shows, the pattern is used to modernize legacy systems and keep applications decoupled, allowing a dev team to update pieces of the application without causing application wide issues. With low coupling, one can scale only the most intensive pieces of your application and plan how to engineer for failures within your application. The further benefits this microservice architecture achieves is polyglot programs and polyglot storage — the right tools for the right job.
Domain-Driven-Design
Domain-Driven Design (DDD) can be useful while designing a system, especially when introducing new technologies.
Domain-Driven Design(DDD) is a collection of principles and patterns that help developers craft elegant object systems. Properly applied it can lead to software abstractions called domain models. These models encapsulate complex business logic, closing the gap between business reality and code. ~ Microsoft Learn: Best Practice — An Introduction To Domain-Driven Design
bad-inc.net is a fictional application that has recently gained a lot of popularity due to its innovative features, user-friendly applications, and seamless user experience for villainous deeds. It is a social board where villains can upload nemesis to see who they should watch out for and — buy merch. This has resulted in millions of daily active users (DAU), which has caused the company’s Engineering department to grow substantially. However, the department has started to face challenges in keeping up with demand and success. They are finding it difficult to release features promptly and distribute work effectively across the department. Initially, they tried dividing teams by large applications, but this did not solve the issue. They noticed multiple teams trying to solve the same problems and caused too-many-cooks-in-the-kitchen situation. Therefore, they have decided to apply Domain-Driven Design (DDD) principles to reorganize their teams and systems for better efficiency and productivity.
To start, we define bounded contexts that delineate areas of interest. Here are the contexts we are concerned with in this article:
- Users
- Notifications
- Nemesis
Small teams are formed when engineers pick the context they would enjoy contributing to, or fill in needed positions for those teams, this is when contexts become products. We have 2 teams at Bad, inc. (Team Evil and Team Platypus) which means a couple of teams may have more than one product to work on. This will decouple the application, encourage engineers to innovate solutions, and allow teams to work at their own pace, unaffected by other teams, to an extent. Here is the overview of the projects and services without implementation details. The dotted borders represent the bounded context, where the service should only care about meeting the needs of such context, the service is declared inside. The dotted arrows represent asynchronous communication across contexts, while the full arrows represent synchronous communication such as gRPC or REST.

After applying DDD, we have disparate systems, so how do these stitch together to create the application the users want? Let’s take a closer look at the technology that can be implemented to help integrate these systems!
API Gateways

Application Programming Interface (API) Gateways act as a central Uniform Resource Identifier (URI) for your backend services. This allows client-side apps to interface with the single URI to communicate with the services needed, the Gateway will direct the requests to the service that is declared for that route such as api.mygateway.com/service1. If you have some experience with load balancers, ingresses, or reverse proxies, this behavior seems similar, and it is; however, API Gateways use service discovery techniques to decouple the Gateway from the services and tend to be more feature-rich.
API Gateways often provide other benefits such as Authentication and Authorization. You can verify JSON Web Tokens (JWT) that help identify the user sending this request to the API Gateway. Instead of concerning other services with business logic for Auth, or using another service to verify the credentials, the Gateway lifts this burden and keeps services focused on a single point of responsibility.
Other common API Gateway abilities are:
- Rate Limiting
- Caching responses
- Circuit Breaking, route requests to the next best service if one is down
- Built-in logging and traffic traces for debugging the application
- Protocol conversion, allowing RPC, SOAP, and GraphQL protocols to be used together
The biggest advantage of an API Gateway is that it decouples your system and even allows building strangler patterns around older systems to convert them to more modern tech stacks!
Communication Between Services and Message Queues
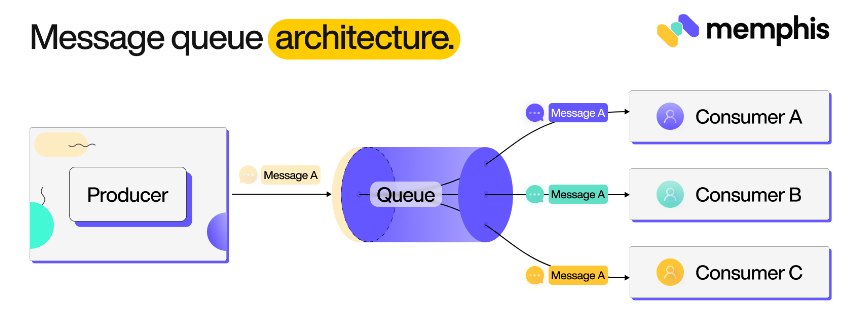
An API Gateway allows outside communication to your backend system, but what if Team Evil needs its backend services to communicate with Team Platypus’s services? This can create a coupling between the services and dependency on two contexts. Instead, we can use Message Queues to ensure our services can stay decoupled. Message Queues and Message Brokers are two useful asynchronous tools for service-to-service communication, both involve event producers and have event consumers, but queues rely on the consumer to poll the event and remove it from the queue when processed, while brokers will push the event to a consumer. This pattern is commonly known as a publisher/subscriber pattern.
A common practice is to create REST endpoints for your services and enable your services to call them directly. Although there is nothing wrong with this approach, you will need to start thinking about your services’ ability to handle the load of numerous service requests for the same task and create synchronous communication between your backend services. This can lead to coupled services, where if one service goes down, your app can be crippled.
This is a topic for another article, but another potential tool for this situation is a Stream. Streams also use the pub/sub pattern and can be used for real-time applications. A couple of popular choices would be Kafka and AWS Kinesis. These Streams can be highly performant and scalable with the cost of overhead.
A Local Look At The Tools in Action
I created a small application that is overly complex, where in a real-life scenario you may want to make this as a monolith, but for this demonstration, I wanted to show off these fun tools to help decouple services! We will not get too in-depth with Go or the business logic behind the application. If you are interested, please check out my GitHub repo and other helpful resources like go.dev
git clone https://github.com/joshbrgs/medium-tutorials.git
cd medium-tutorials
cd stop-wasting-working-software
cp .env.example .env
docker compose up -d rabbitMq
docker compose up -d kong
We have just spun up some docker containers for a message queue (Rabbit MQ) and an API gateway (Kong). You can check these out now on http://localhost:15672 (password and user are both “guest” by default) and http://localhost:8002 respectively. You will not see much traffic at first because we have not started up the app completely! Run this command one last time and see how Kong uses autodiscovery for the ports and services, and meanwhile, the applications that need the queue, have the appropriate connection made within their code.
docker compose up -d
Now the complete application should be running in docker containers. Communication will happen when you start to use the API.
The applications using gRPC could also use gRPC with the API Gateway. I have the containers running as private workloads for internal communication only, no public user can use the gateway to invoke the services. In a production scenario, the endpoints of these services would not be exposed like they are with Docker at the moment, only the gateway. Use Postman or another service that can communicate with an API to interact with Bad Inc.’s new application!
Feel free to use something like Postman instead if you do not want to just curl the app. I have included a Postman collection with the repository! Just import it and it will even handle storing the JWT in the header for you.
#Getting a 401 due to not being authorized, the Gateway uses our Auth service as the
#keeper to guard our APIs from the Heros
curl http://localhost:8000/notify
#Create User
curl -X POST http://localhost:8000/create-user -H 'Content-Type: application/json'
-d '{"username":"mrmean","password":"my_password"}'
#Login
curl http://localhost:8000/login -u "mrmean:my_password"
#Replace the token part with the JWT returned back from logging in
#Create Nemesis
curl -X POST http://localhost:8000/nemesis -H "Authorization: Bearer {token}" -H 'Content-Type: application/json' -d '{"Id": 1, "Nemesis": "Perry Bond", "Power": 8}'
#List Nemesis
curl http://localhost:8000/nemesis -H "Authorization: Bearer {token}"
#List Notifications
curl http://localhost/notify -H "Authorization: Bearer {token}"
Now, if you watch the RabbitMq’s dashboard, you should be able to find that the application is populating the queue. This is giving an example of Protocol conversion of http to gRPC, a central Auth service protecting routes unless authenticated, and the services using a message queue for inter service communication (you can message over JSON payloads not just strings). Feel free to look at Kong’s UI and investigate possibilities an API Gateway can do for you!
Bonus: Service Meshes

Service Meshes are similar to API Gateways in that they can provide circuit breaker patterns, tracing, and traffic management rules; however, unlike API Gateways, Service Meshes have a central controller layer and a distributed data layer, reducing the likelihood of a Single Point of Failure. By leveraging the network, Service Meshes make service-to-service communication easier, and easily enable mTLS (mutual Transport Layer Security), a security measure that businesses usually prefer. While Service Meshes can create a large amount of complexity, it can also provide significant benefits. It’s important to note that we don’t have to choose between Service Meshes, Message Queues, and API Gateways. Sometimes scenarios may call for all of them.
Conclusion
Architecting decoupled applications can be a difficult game of trade-offs. Tooling has constantly evolved in the industry trying to lift the burden of interservice communication and empowering teams to develop evolvable and scalable services. Message Queues help provide a pub/sub pattern for your services to communicate without necessarily depending on each other, while API Gateways and Meshes provide an orchestration of traffic flow between your services. If you want some services with less overhead, the majority of Cloud Providers offer these services as well, which fully integrate into the other services like Lambda functions and Elastic Kubernetes Service!
References
- bliki: Bounded Context
- Enabling Seamless Kafka Async Queuing with Consumer Proxy
- Memphis.dev - What is a message queue?
- Traefik Proxy Documentation - Traefik
- RabbitMQ Tutorials
- Kong Gateway | Kong Docs